Vectorとは

現在参画している現場で、ログコレクターとしてVectorを利用しています。
本記事ではVectorの紹介と併せて、Kubernetes環境へデプロイできるようにHelmChart化してみたいと思います。
ログコレクターとは
ログコレクターは複数のソース (ファイル、system など) からログを収集します。
メタデータによるエントリの追加、解析、フィルタリングなどを含む、ログの変換操作を実行できます。
収集したログはSplunkなどのコンポーネントに送信されます。
Vectorとは
OSSのRust製データパイプライン(エージェント)で、可観測性データ(ログ・メトリクス)の収集・変換・送信を行います。
大きく「Sources」「Transforms」「Sinks」の3コンポーネントで構成されています。
様々なデータを収集することが可能で、送信先として指定可能な製品(Splunk、ElasticSerach、Grafana Loki ...)も幅広くサポートされています。
詳細は公式ドキュメントを参照してください。
Vectorの性能
Fluentd等の他エージェントに比べると、高速でメモリ効率が高く、要求の厳しいワークロードの処理に適しているようです。
パフォーマンス比較については、以下の記事が参考になります。
HelmChart
ディレクトリ構成は以下となります。
. |-- Chart.yaml |-- templates | |-- vector-config.yaml | |-- vector-daemonset.yaml | |-- vector-rbac.yaml | |-- vector-service-account.yaml | `-- vector-service.yaml `-- values.yaml
templates/vector-daemonset.yaml
VectorをDaemonSetで定義して、各ノードのコンテナログ(/var/log/pods)を参照できるようにします。
kube-config を参照する必要があるため、SecretにしてVolumeMountしています。
apiVersion: apps/v1 kind: DaemonSet metadata: name: "{{ .Release.Name }}-daemonset" spec: selector: matchLabels: app: "{{ .Release.Name }}-app" template: metadata: labels: app: "{{ .Release.Name }}-app" spec: serviceAccountName: "{{ .Release.Name }}-vector-sa" containers: - name: "{{ .Release.Name }}-app" image: "{{ .Values.vector.image.repository }}:{{ .Values.vector.image.tag }}" args: ["--config", "/etc/vector/vector.toml"] readinessProbe: httpGet: path: /health port: 8686 initialDelaySeconds: 60 periodSeconds: 60 livenessProbe: httpGet: path: /health port: 8686 initialDelaySeconds: 60 periodSeconds: 60 volumeMounts: - name: config-volume mountPath: /etc/vector readOnly: true - name: kube-config mountPath: /mnt/vector readOnly: true - name: pod-logs mountPath: /var/log/pods readOnly: true env: - name: TZ value: Asia/Tokyo - name: VECTOR_SELF_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: VECTOR_CONFIG_PATH value: /etc/vector/vector.toml ports: - containerPort: 8686 volumes: - name: config-volume configMap: name: "{{ .Release.Name }}-config" - name: kube-config secret: secretName: kube-config - name: pod-logs hostPath: path: /var/log/pods tolerations: - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule"
kube-config
Secret化するkube-config は、以下のような内容となります。
kubectl create secret generic kube-config --from-file=kube-config -n xxx でVectorと同じnamespaceにデプロイしてください。
apiVersion: v1 clusters: - cluster: certificate-authority-data: xxxx server: https://kubernetes.default.svc:443 name: default contexts: - context: cluster: default user: default name: default current-context: default kind: Config preferences: {} users: - name: default user: xxxx client-key-data: xxxx
templates/vector-config.yaml
次にConfigMapです。
Vectorの設定ファイルをConfigMap化しています。
sources.kubernetes_logs.kube_config_fileにDaemonSetでマウントしたkube-configのパスを指定する必要がありますtransforms.transform_logsでログの変換やフィルタリングの設定をしていますsinks.lokiでログの送信先に Grafana Loki のURLを指定しています
apiVersion: v1 kind: ConfigMap metadata: name: "{{ .Release.Name }}-config" data: vector.toml: |- # Vector の設定ファイル [api] enabled = true address = "0.0.0.0:8686" [sources.kubernetes_logs] type = "kubernetes_logs" ignore_older_secs = 1800 max_read_bytes = 10485760 max_line_bytes = 1048576 read_from = "end" timezone = "Asia/Tokyo" kube_config_file = "/mnt/vector/kube-config" extra_namespace_label_selector = """ kubernetes.io/metadata.name!=default, kubernetes.io/metadata.name!=kube-system """ [transforms.transform_logs] type = "remap" inputs = [ "kubernetes_logs" ] source = """ .pod = .kubernetes.pod_name .namespace = .kubernetes.pod_namespace .container = .kubernetes.container_name del(.file) del(.kubernetes) del(.source_type) del(.stream) """ timezone = "Asia/Tokyo" [sinks.loki] type = "loki" inputs = ["transform_logs"] compression = "snappy" endpoint = "{{ .Values.loki.address }}" path = "/loki/api/v1/push" out_of_order_action = "drop" remove_timestamp = false [sinks.loki.encoding] codec = "json" timestamp_format = "rfc3339" [sinks.loki.labels] job = "k8s-logs" env = "{{ .Values.loki.env }}"
各設定項目の詳細は公式ドキュメントを参照してください。
- https://vector.dev/docs/reference/configuration/sources/kubernetes_logs/
- https://vector.dev/docs/reference/configuration/transforms/remap/
- https://vector.dev/docs/reference/configuration/sinks/loki/
その他のマニフェストについて特筆すべき点はないため、詳細は割愛します。
# Chart.yaml apiVersion: v2 name: vector-agent description: A Helm chart for Vector Agent version: 1.0.0
# values.yaml vector: image: repository: "docker.io/timberio/vector" tag: "0.29.1-alpine" service: type: ClusterIP loki: address: "http://loki-stack.logging.svc:3100" env: dev
# templates/vector-service.yaml apiVersion: v1 kind: Service metadata: name: "{{ .Release.Name }}-service" spec: selector: app: "{{ .Release.Name }}-app" ports: - name: http port: 8686 targetPort: 8686 type: "{{ .Values.vector.service.type }}"
# templates/vector-service-account.yaml apiVersion: v1 kind: ServiceAccount metadata: name: "{{ .Release.Name }}-vector-sa"
# templates/vector-rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: "{{ .Release.Name }}-vector-clusterrole" rules: - apiGroups: [""] resources: ["pods", "pods/log", "nodes", "namespaces", "deployments", "statefulsets"] verbs: ["get", "list", "watch"] - apiGroups: ["apps"] resources: ["daemonsets"] verbs: ["get", "list", "watch"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: "{{ .Release.Name }}-vector-rolebinding" subjects: - kind: ServiceAccount name: "{{ .Release.Name }}-vector-sa" namespace: {{ .Release.Namespace | quote }} roleRef: kind: ClusterRole name: "{{ .Release.Name }}-vector-clusterrole" apiGroup: rbac.authorization.k8s.io
上記のChartをhelmコマンドでデプロイしてみます。
$ helm version version.BuildInfo{Version:"v3.10.2", GitCommit:"50f003e5ee8704ec937a756c646870227d7c8b58", GitTreeState:"clean", GoVersion:"go1.18.8"} # dry run $ helm install vector-test ./vector-agent-helm-chart/ --dry-run --namespace test-ns --create-namespace NAME: vector-test LAST DEPLOYED: Fri May 12 16:08:49 2023 NAMESPACE: test-ns STATUS: pending-install REVISION: 1 TEST SUITE: None HOOKS: MANIFEST: --- # Source: vector-agent/templates/vector-service-account.yaml apiVersion: v1 kind: ServiceAccount metadata: name: "vector-test-vector-sa" ... $ helm install vector-test ./vector-agent-helm-chart/ --namespace test-ns --create-namespace NAME: vector-test LAST DEPLOYED: Fri May 12 16:10:48 2023 NAMESPACE: test-ns STATUS: deployed REVISION: 1 TEST SUITE: None
Vectorを使ってみて
2023年5月現在、複数行のログがそれぞれ別レコードとして扱われてしまうので、Grafanaで可視化した際に見づらいと感じました。
コンテナのログをJSONで出力するなどしないと、単一データとして扱われないようです。
改行の扱いについては、以下の記事も参考になります。
まとめ
Vectorの紹介とHelmChartにしてデプロイしてみました。
OpenShiftではFluentd が非推奨となり、代わりにVectorが採用されています。
また、Vectorには以下のような特徴があります。
- ログ・メトリクス収集が可能なエージェント(Fluentdとほぼ同等)
- 高性能(高速でメモリ効率が高い、CPU消費は多め)
- Splunk、ElasticSerachなど大体の製品に対応している
参考リンク
- https://github.com/vectordotdev/vector#performance
- https://medium.com/ibm-cloud/log-collectors-performance-benchmarking-8c5218a08fea
- https://docs.openshift.com/container-platform/4.12/logging/cluster-logging.html#collector-features
- https://access.redhat.com/ja/articles/7009795
- https://access.redhat.com/documentation/ja-jp/openshift_container_platform/4.11/html-single/logging/index#doc-wrapper
Gitレポジトリ。
公式のHelmChart。
コンテナイメージはtimberio/vectorという名前で、Dockerhubに公開されています。
【Kubernetes】k8s上のPodmanコンテナでDockerイメージをビルドする

現在、PJでk3上にJenkinsのCICDパイプラインを構築しています。
その中でDockerイメージのビルドはkanikoで行っているのですが、メンテに不安がある為、Podmanに置き換える事になりました。
kanikoについてはこちらの記事で紹介しています。
Podmanとは
Red Hatのエンジニアがオープンソース・コミュニティと共に開発した、コンテナを管理、実行する為のOSSツールです。
デーモンレスである点とroot権限が無くても動く事が大きな特徴だと思います。
参考
以下の記事を参考にしました。
- How to use Podman inside of a container | Enable Sysadmin
- How to use Podman inside of Kubernetes | Enable Sysadmin
- Best practices for running Buildah in a container | Red Hat Developer
- Build and run Buildah inside a Podman container | Red Hat Developer
- Podman in Docker を試してみた
構成
Podmanでレジストリにイメージをプッシュできる所まで確認したいので、Docker Desktopのk8上に以下のコンテナを起動して、動作確認したいと思います。
ディレクトリ構成
./ ├── conf │ └── registries.conf ├── input │ ├── Dockerfile │ └── nginx.conf ├── Dockerfile ├── coredns-cm.yml ├── htpasswd-secret.yml └── podman-k8s.yml
起動
conf/registries.conf
Podmanから参照するレジストリに関する設定ファイルです。
private.registry.local は今回作成するDockerレジストリのホスト名です。
[registries.search] registries = ['docker.io', 'quay.io'] [registries.insecure] registries = ['private.registry.local']
Dockerfile
Podman実行用イメージのDockerfileです。
/var/lib/share配下はうまく使われていないように思うのですが、今回は割愛😇
FROM alpine:latest
ENV _CONTAINERS_USERNS_CONFIGURED ""
RUN apk --no-cache add podman tzdata fuse-overlayfs slirp4netns curl
RUN sed -i -e 's|^#mount_program|mount_program|g' -e 's|^# rootless_storage_path|rootless_storage_path|g' \
-e '/additionalimage.*/a "/var/lib/shared"' -e 's|^mountopt[[:space:]]*=.*$|mountopt = "nodev,fsync=0"|g' /etc/containers/storage.conf \
&& adduser --disabled-password podman \
&& echo "podman:100000:65536" >> /etc/subuid \
&& echo "podman:100000:65536" >> /etc/subgid \
&& mkdir -p -m 755 /home/podman/.local/share/containers/storage \
/var/lib/shared/overlay-images /var/lib/shared/overlay-layers \
/var/lib/shared/vfs-images /var/lib/shared/vfs-layers \
&& touch /var/lib/shared/overlay-images/images.lock \
&& touch /var/lib/shared/overlay-layers/layers.lock \
&& touch /var/lib/shared/vfs-images/images.lock \
&& touch /var/lib/shared/vfs-layers/layers.lock \
&& chown podman:podman -R /home/podman /var/lib/shared \
&& mknod /dev/fuse -m 0666 c 10 229
COPY conf/registries.conf /etc/containers/registries.conf
USER podman
WORKDIR /home/podman
CMD [ "sh", "-c", "while true; do sleep 1000; done" ]
ビルドしておきます。
$ docker build -t test-podman .
coredns-cm.yml
k8sの組込みDNSサーバーであるCoreDNSの設定ファイルを修正して、クラスタ内でレジストリのホスト名が名前解決できるようにします。
$ alias k=kubectl # 設定ファイルがConfigMapとなっているので、取得して修正します $ k get cm -n kube-system coredns -o yaml > coredns-cm.yml # 以下の内容で修正 $ vi coredns-cm.yml apiVersion: v1 data: Corefile: | .:53 { errors health { lameduck 5s } ### ここから hosts { <自サーバーのIP> private.registry.local fallthrough } ### ここまでを追加 ready kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 forward . /etc/resolv.conf { max_concurrent 1000 } cache 30 loop reload loadbalance } kind: ConfigMap metadata: name: coredns namespace: kube-system # 適用 $ k apply -f coredns-cm.yml
適用したら、DockerDesktopを再起動します。
CoreDNSポッド自体を再起動でもOK。
htpasswd-secret.yml
Dockerレジストリにログインする際のユーザー情報をSecretに登録します。
認証情報は以下のコマンドで生成しました。
# ユーザー名: podman-user、パスワード: fa0e473e6a60d3f7 $ docker run -it httpd:2.4.39-alpine htpasswd -nb -B podman-user fa0e473e6a60d3f7 > htpasswd # base64エンコードして出力 $ cat htpasswd | base64 xxxxx... # 出力結果をSecretに設定 $ cat htpasswd-secret.yml apiVersion: v1 kind: Secret metadata: name: htpasswd-secret data: htpasswd: <base64エンコードした認証情報> # 適用 $ k apply -f htpasswd-secret.yml
podman-k8s.yml
Ingressを使用するので、先にingress-nginxコントローラーをインストールします。
$ k apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.4.0/deploy/static/provider/cloud/deploy.yaml
インストールしたら、以下のマニフェストを適用します。
$ cat podman-k8s.yml apiVersion: apps/v1 kind: Deployment metadata: name: podman labels: app: podman spec: replicas: 1 selector: matchLabels: app: podman template: metadata: labels: app: podman spec: containers: - name: podman image: test-podman imagePullPolicy: Never resources: limits: cpu: 200m memory: 500Mi env: - name: DOCKER_REGISTRY_USER value: "podman-user" - name: DOCKER_REGISTRY_PASSWD value: "fa0e473e6a60d3f7" # わかりやすくする為にそのまま記載しています。要Secret化 securityContext: privileged: true runAsUser: 1000 capabilities: drop: - NET_ADMIN - SYS_ADMIN - SYS_CHROOT - name: registry image: registry resources: limits: cpu: 100m memory: 100Mi ports: - containerPort: 5000 name: http protocol: TCP env: - name: REGISTRY_HTTP_SECRET value: a1f47b1c62945b5d - name: REGISTRY_AUTH value: htpasswd - name: REGISTRY_AUTH_HTPASSWD_REALM value: "Registry Realm" - name: REGISTRY_AUTH_HTPASSWD_PATH value: /auth/htpasswd - name: REGISTRY_HTTP_ADDR value: 0.0.0.0:5000 - name: REGISTRY_STORAGE_DELETE_ENABLED value: "true" volumeMounts: - mountPath: /auth name: htpasswd-secret-volume readOnly: true - name: registry-ui image: klausmeyer/docker-registry-browser:latest resources: limits: cpu: 100m memory: 200Mi ports: - containerPort: 8080 name: http protocol: TCP env: - name: DOCKER_REGISTRY_URL value: "http://private.registry.local" - name: ENABLE_DELETE_IMAGES value: "true" volumes: - name: htpasswd-secret-volume secret: secretName: htpasswd-secret items: - key: htpasswd path: htpasswd mode: 0400 --- apiVersion: v1 kind: Service metadata: name: registry-ui-svc labels: app: registry-ui-svc spec: type: ClusterIP selector: app: podman ports: - protocol: TCP port: 80 targetPort: 8080 name: registry-ui --- apiVersion: v1 kind: Service metadata: name: registry-svc labels: app: registry-svc spec: type: ClusterIP selector: app: podman ports: - protocol: TCP port: 80 targetPort: 5000 name: registry --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: podman-ingress annotations: nginx.ingress.kubernetes.io/proxy-body-size: 2G spec: ingressClassName: "nginx" rules: - host: private.registry.local http: paths: - path: / pathType: Prefix backend: service: name: registry-svc port: number: 80 - host: localhost http: paths: - path: / pathType: Prefix backend: service: name: registry-ui-svc port: number: 80 # 適用 $ k apply -f podman-k8s.yml deployment.apps/podman created service/registry-ui-svc created service/registry-svc created ingress.networking.k8s.io/podman-ingress created # 起動していることを確認 $ k get po,svc,ing NAME READY STATUS RESTARTS AGE pod/podman-6c6fd4c55f-sqh64 3/3 Running 0 22s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP xxx.xxx.xxx.xxx <none> 443/TCP 28h service/registry-svc ClusterIP xxx.xxx.xxx.xxx <none> 80/TCP 22s service/registry-ui-svc ClusterIP xxx.xxx.xxx.xxx <none> 80/TCP 22s NAME CLASS HOSTS ADDRESS PORTS AGE ingress.networking.k8s.io/podman-ingress nginx private.registry.local,localhost 80 22s
http://localhostにアクセスすると、レジストリのWebUIが表示されます。
動作確認
PodmanのPODでイメージをビルドして、レジストリにpushまでしてみます。
$ k get po NAME READY STATUS RESTARTS AGE podman-6c6fd4c55f-sqh64 3/3 Running 0 5m21s $ k exec -it podman-6c6fd4c55f-sqh64 -c podman -- sh # ログイン ~ $ echo "${DOCKER_REGISTRY_PASSWD}" | podman login -u ${DOCKER_REGISTRY_USER} --password-stdin private.registry.local WARN[0000] "/" is not a shared mount, this could cause issues or missing mounts with rootless containers Login Succeeded! # ubuntuをpullして、レジストリ用のタグを付与します ~ $ podman pull ubuntu ✔ docker.io/library/ubuntu:latest Trying to pull docker.io/library/ubuntu:latest... Getting image source signatures Copying blob e96e057aae67 done Copying config a8780b506f done Writing manifest to image destination Storing signatures a8780b506fa4eeb1d0779a3c92c8d5d3e6a656c758135f62826768da458b5235 ~ $ podman tag docker.io/library/ubuntu private.registry.local/ubuntu ~ $ podman images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/library/ubuntu latest a8780b506fa4 3 days ago 80.3 MB private.registry.local/ubuntu latest a8780b506fa4 3 days ago 80.3 MB # レジストリにプッシュ ~ $ podman push private.registry.local/ubuntu Getting image source signatures Copying blob f4a670ac65b6 done Copying config a8780b506f done Writing manifest to image destination Storing signatures ~ $ exit
今度はDockerfileから作成したイメージを、レジストリにプッシュしてみます。
$ mkdir input $ vi input/Dockerfile # ネットからコピペしてきた、nginxを動かすだけのイメージです $ cat input/Dockerfile FROM centos:7 RUN yum update -y && yum clean all RUN yum install -y http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm RUN yum install -y --enablerepo=nginx nginx RUN yum swap -y fakesystemd systemd && yum clean all ADD nginx.conf /etc/nginx/conf.d/ RUN mv /etc/nginx/conf.d/default.conf /etc/nginx/conf.d/default.conf.bk RUN systemctl enable nginx EXPOSE 80 ENTRYPOINT ["/usr/sbin/nginx", "-g", "daemon off;", "-c", "/etc/nginx/nginx.conf"] $ vi input/nginx.conf $ cat input/nginx.conf server { listen 80 default_server; root /var/www/html; index index.html index.htm; server_name nginx; location / { try_files $uri $uri/ =404; } }
Podmanコンテナに↑のファイルをcpします。
$ k cp input podman-6c6fd4c55f-sqh64:/home/podman -c podman $ k exec -it podman-6c6fd4c55f-sqh64 -c podman -- sh # コピーされたことを確認 ~ $ ls input/ Dockerfile nginx.conf # イメージをビルドする ~ $ podman build -t private.registry.local/test-nginx:0.0.1 input STEP 1/10: FROM centos:7 ✔ docker.io/library/centos:7 Trying to pull docker.io/library/centos:7... Getting image source signatures Copying blob 2d473b07cdd5 done Copying config eeb6ee3f44 done Writing manifest to image destination Storing signatures STEP 2/10: RUN yum update -y && yum clean all Loaded plugins: fastestmirror, ovl ..... STEP 10/10: ENTRYPOINT ["/usr/sbin/nginx", "-g", "daemon off;", "-c", "/etc/nginx/nginx.conf"] COMMIT private.registry.local/test-nginx:0.0.1 --> 615f0d391a9 Successfully tagged private.registry.local/test-nginx:0.0.1 615f0d391a99dfadb871b55ae23fb519e38a73c6ab53f2c8aa25f21497838926 # 作成したイメージをプッシュ ~ $ podman push private.registry.local/test-nginx:0.0.1 Getting image source signatures Copying blob d2af15141490 done Copying blob 174f56854903 done Copying blob caa980c80a8b done Copying blob 66ef84f422dc done Copying blob 26dcfab9f201 done Copying blob b357d4ab9171 done Copying blob faa8fdc2852c done Copying blob 9473b225969a done Copying config 615f0d391a done Writing manifest to image destination Storing signatures ~ $
ブラウザに戻ってリロードすると、プッシュしたイメージが表示されている事が確認できます。
注意
PodmanやBuildahでビルドしたイメージは、デフォルトでOCI Image Formatとなっています。
古めのレジストリにプッシュする場合、OCI Image Formatに対応していない可能性があります。
その場合、ビルド時に--format dockerを付与するとプッシュ可能となります。
また、プッシュ時に--format v2s2を付与しても良いようです。
【Docker】コンテナ上にHadoop + Spark実行環境を構築する

+

案件でHadoopを扱う事になりそうなので、勉強のためにDockerコンテナでHadoop + Spark環境を構築してみました。擬似分散モードでの起動を想定しています。
ソースコードはgit hubに上げてあります。
Hadoopのインストール
公式サイトからファイルをダウンロードする必要があります。
配布されているHadoopのバージョンは以下URLから確認できます。
Sparkのインストール
Sparkも公式サイトからダウンロードします。
ダウンロードするHadoopのバージョンと同じ物をChoose a package typeのセレクトボックスから選択します。
Dockerfile
公式サイトに環境構築手順がありますので、そちらを参考に各ツールのインストールと設定ファイルを配置します。
HadoopとSparkのダウンロードURLは、先述の公式サイトから確認できます。
FROM openjdk:8
ENV HADOOP_VERSION 2.10.2
ENV HADOOP_HOME=/hadoop-${HADOOP_VERSION}
ENV HADOOP_OPTS "-Djava.library.path=${HADOOP_HOME}/lib/native"
ENV HADOOP_PREFIX ${HADOOP_HOME}
ENV HADOOP_COMMON_HOME ${HADOOP_HOME}
ENV HADOOP_HDFS_HOME ${HADOOP_HOME}
ENV HADOOP_MAPRED_HOME ${HADOOP_HOME}
ENV HADOOP_YARN_HOME ${HADOOP_HOME}
ENV HADOOP_CONF_DIR ${HADOOP_HOME}/etc/hadoop
ENV YARN_CONF_DIR $HADOOP_PREFIX/etc/hadoop
ENV SPARK_HOME=/usr/local/lib/spark
ENV PATH=${HADOOP_HOME}/bin:${SPARK_HOME}/bin:$PATH
RUN apt-get update \
&& apt-get install -y --no-install-recommends ssh \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& wget -q -O - http://ftp.yz.yamagata-u.ac.jp/pub/network/apache/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz | tar zxf - \
&& wget https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop2.tgz \
&& tar zxvf spark-3.3.0-bin-hadoop2.tgz -C /usr/local/lib/ \
&& ln -s /usr/local/lib/spark-3.3.0-bin-hadoop2 /usr/local/lib/spark \
&& rm spark-3.3.0-bin-hadoop2.tgz
USER ${USERNAME}
WORKDIR /hadoop-${HADOOP_VERSION}
COPY config ./etc/hadoop/
COPY start ./
COPY main.py ./
RUN mkdir -p /run/sshd /data \
&& ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa \
&& cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys \
&& chmod 0600 /root/.ssh/authorized_keys \
&& hdfs namenode -format
CMD ["./start"]
start
Hadoop起動後にコンテナが停止しないようにsleep処理を実行しています。
#!/bin/bash /usr/sbin/sshd /hadoop-${HADOOP_VERSION}/sbin/start-dfs.sh /hadoop-${HADOOP_VERSION}/sbin/start-yarn.sh # daemonize while true; do sleep 1000 done
main.py
ネットで拾ってきた、Spark submit実行用のPythonファイルです。
# -*- coding: utf-8 -*- from pyspark import SparkContext, RDD from typing import List, Dict def main(): # inputデータ(試験の結果) input_data: List[Dict[str, int]] = [ {'国語': 86, '算数': 57, '理科': 45, '社会': 100}, {'国語': 67, '算数': 12, '理科': 43, '社会': 54}, {'国語': 98, '算数': 98, '理科': 78, '社会': 69}, ] # SparkContext, RDD作成 sc: SparkContext = SparkContext(appName='spark_sample') rdd: RDD = sc.parallelize(input_data) # 各教科および合計点の平均点を計算 output: Dict[str, float] = rdd\ .map(lambda x: x.update(合計=sum(x.values())) or x)\ .flatMap(lambda x: x.items())\ .groupByKey()\ .map(lambda x: (x[0], round(sum(x[1]) / len(x[1]), 2)))\ .collect() print(output) if __name__ == '__main__': main()
設定ファイル
疑似分散モードの設定とYARN、Sparkを適用する為の各種configファイルです。
config/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
config/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/datanode</value>
</property>
</configuration>
config/hadoop-env.sh
設定内容の詳細は、以下の記事が参考になります。
export JAVA_HOME=/usr/local/openjdk-8 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HADOOP_SSH_OPTS="-o StrictHostKeyChecking=no -o BatchMode=yes" export HADOOP_OPTS="${HADOOP_OPTS} -XX:-PrintWarnings -Djava.net.preferIPv4Stack=true -Djava.library.path=${HADOOP_HOME}/lib/native"
config/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
config/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
起動
イメージをビルドして、コンテナを起動します。
$ docker build -t test-hadoop . $ docker run -itd --name test-hadoop --rm -p 50070:50070 -p 8088:8088 test-hadoop $ docker exec -it test-hadoop bash
少し待つとWeb UIにアクセスできます。


実行
MapReduceのサンプルである「Wordcount」を実行してみます。
# input配置先を作成 root@2b017152af10:/hadoop-2.10.2# hdfs dfs -mkdir -p /user/root/input # Wordcountの資材をinputに配置 root@2b017152af10:/hadoop-2.10.2# hdfs dfs -put etc/hadoop/* /user/root/input # Wordcountを実行 root@2b017152af10:/hadoop-2.10.2# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar wordcount input output 22/10/15 08:28:58 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 22/10/15 08:28:59 INFO input.FileInputFormat: Total input files to process : 30 22/10/15 08:28:59 INFO mapreduce.JobSubmitter: number of splits:30 22/10/15 08:28:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1665818375854_0002 22/10/15 08:28:59 INFO conf.Configuration: resource-types.xml not found 22/10/15 08:28:59 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 22/10/15 08:28:59 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE 22/10/15 08:28:59 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE 22/10/15 08:28:59 INFO impl.YarnClientImpl: Submitted application application_1665818375854_0002 22/10/15 08:28:59 INFO mapreduce.Job: The url to track the job: http://2b017152af10:8088/proxy/application_1665818375854_0002/ 22/10/15 08:28:59 INFO mapreduce.Job: Running job: job_1665818375854_0002 22/10/15 08:29:06 INFO mapreduce.Job: Job job_1665818375854_0002 running in uber mode : false 22/10/15 08:29:06 INFO mapreduce.Job: map 0% reduce 0% 22/10/15 08:29:22 INFO mapreduce.Job: map 20% reduce 0% 22/10/15 08:29:33 INFO mapreduce.Job: map 40% reduce 0% 22/10/15 08:29:41 INFO mapreduce.Job: map 43% reduce 0% 22/10/15 08:29:42 INFO mapreduce.Job: map 57% reduce 0% 22/10/15 08:29:47 INFO mapreduce.Job: map 60% reduce 0% 22/10/15 08:29:48 INFO mapreduce.Job: map 67% reduce 0% 22/10/15 08:29:49 INFO mapreduce.Job: map 73% reduce 0% 22/10/15 08:29:53 INFO mapreduce.Job: map 77% reduce 24% 22/10/15 08:29:54 INFO mapreduce.Job: map 80% reduce 24% 22/10/15 08:29:55 INFO mapreduce.Job: map 83% reduce 24% 22/10/15 08:29:56 INFO mapreduce.Job: map 90% reduce 24% 22/10/15 08:29:58 INFO mapreduce.Job: map 93% reduce 24% 22/10/15 08:29:59 INFO mapreduce.Job: map 97% reduce 30% 22/10/15 08:30:00 INFO mapreduce.Job: map 100% reduce 30% 22/10/15 08:30:01 INFO mapreduce.Job: map 100% reduce 100% 22/10/15 08:30:02 INFO mapreduce.Job: Job job_1665818375854_0002 completed successfully 22/10/15 08:30:02 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=79549 FILE: Number of bytes written=6694130 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=89584 HDFS: Number of bytes written=42991 HDFS: Number of read operations=93 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 .... File Input Format Counters Bytes Read=85990 File Output Format Counters Bytes Written=42991 # 「output/part-r-00000」がジョブの出力結果 root@2b017152af10:/hadoop-2.10.2# hdfs dfs -ls output Found 2 items -rw-r--r-- 1 root supergroup 0 2022-10-15 08:29 output/_SUCCESS -rw-r--r-- 1 root supergroup 42991 2022-10-15 08:29 output/part-r-00000 # 出力内容をcat root@2b017152af10:/hadoop-2.10.2# hdfs dfs -cat output/part-r-00000 | head != 3 "" 7 "". 4 "$HADOOP_JOB_HISTORYSERVER_HEAPSIZE" 1 "$JAVA_HOME" 2 "$YARN_HEAPSIZE" 1 "$YARN_LOGFILE" 1 "$YARN_LOG_DIR" 1 "$YARN_POLICYFILE" 1 "*" 19 cat: Unable to write to output stream.
spark-shellで見てみます。
root@2b017152af10:/hadoop-2.10.2# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/10/15 08:43:31 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://2b017152af10:4040
Spark context available as 'sc' (master = local[*], app id = local-1665823413103).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_342)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val txtFile = sc.textFile("output/part-r-00000")
txtFile: org.apache.spark.rdd.RDD[String] = output/part-r-00000 MapPartitionsRDD[7] at textFile at <console>:23
scala> txtFile.filter(line => line.contains("apache")).foreach(println)
#dfs.class=org.apache.hadoop.metrics.file.FileContext 1 (0 + 2) / 2]
#jvm.class=org.apache.hadoop.metrics.file.FileContext 1
#jvm.class=org.apache.hadoop.metrics.spi.NullContext 1
#log4j.additivity.org.apache.hadoop.mapreduce.v2.hs.HSAuditLogger=false 1
#log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.statedump=false 1
#log4j.appender.FSSTATEDUMP.layout=org.apache.log4j.PatternLayout 1
#log4j.appender.FSSTATEDUMP=org.apache.log4j.RollingFileAppender 1
#log4j.appender.HSAUDIT.layout=org.apache.log4j.PatternLayout 1
#log4j.appender.HSAUDIT=org.apache.log4j.DailyRollingFileAppender 1
#log4j.appender.HTTPDRFA.layout=org.apache.log4j.PatternLayout 1
#log4j.appender.HTTPDRFA=org.apache.log4j.DailyRollingFileAppender 1
....
rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext 1
rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext31 1
rpc.class=org.apache.hadoop.metrics.spi.NullContext 1
ugi.class=org.apache.hadoop.metrics.ganglia.GangliaContext 1
ugi.class=org.apache.hadoop.metrics.ganglia.GangliaContext31 1
ugi.class=org.apache.hadoop.metrics.spi.NullContext 1
scala> :quit
root@2b017152af10:/hadoop-2.10.2#
次はSpark submitでmain.pyを実行してみます。
root@2b017152af10:/hadoop-2.10.2# spark-submit main.py --master yarn
22/10/15 08:35:30 INFO SparkContext: Running Spark version 3.3.0
22/10/15 08:35:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/10/15 08:35:30 INFO ResourceUtils: ==============================================================
22/10/15 08:35:30 INFO ResourceUtils: No custom resources configured for spark.driver.
22/10/15 08:35:30 INFO ResourceUtils: ==============================================================
22/10/15 08:35:30 INFO SparkContext: Submitted application: spark_sample
22/10/15 08:35:30 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
22/10/15 08:35:30 INFO ResourceProfile: Limiting resource is cpu
....
22/10/15 08:35:37 INFO DAGScheduler: Job 0 finished: collect at /hadoop-2.10.2/main.py:17, took 3.034884 s
[('合計', 269.0), ('国語', 83.67), ('算数', 55.67), ('社会', 74.33), ('理科', 55.33)]
22/10/15 08:35:37 INFO SparkContext: Invoking stop() from shutdown hook
22/10/15 08:35:37 INFO SparkUI: Stopped Spark web UI at http://2b017152af10:4040
22/10/15 08:35:37 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
22/10/15 08:35:37 INFO MemoryStore: MemoryStore cleared
22/10/15 08:35:37 INFO BlockManager: BlockManager stopped
22/10/15 08:35:37 INFO BlockManagerMaster: BlockManagerMaster stopped
22/10/15 08:35:37 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
22/10/15 08:35:37 INFO SparkContext: Successfully stopped SparkContext
22/10/15 08:35:37 INFO ShutdownHookManager: Shutdown hook called
22/10/15 08:35:37 INFO ShutdownHookManager: Deleting directory /tmp/spark-266fe4d6-ea39-4e2e-b6f3-9c67dfed570c
22/10/15 08:35:37 INFO ShutdownHookManager: Deleting directory /tmp/spark-266fe4d6-ea39-4e2e-b6f3-9c67dfed570c/pyspark-05f99759-3773-41f5-b10f-f9aa1f82ef79
22/10/15 08:35:37 INFO ShutdownHookManager: Deleting directory /tmp/spark-74ca53c4-6b39-4ebc-b238-b971849ebaae
root@2b017152af10:/hadoop-2.10.2#
まとめ
Dockerコンテナ上でHadoopとSparkを連携させてみました。
ユーザーがrootのままですが、ちょっと動かしてみたい時などに便利そうですね。
良記事
【AWS】Ansible & KanikoでECRにDockerイメージをpushする

Kubernetesクラスタ上でDockerイメージをビルド&プッシュするためのツール「Kaniko」について、仕様を調査したのでメモ。
Kanikoとは
実体はKubernetesクラスタ上でDockerイメージをビルド、プッシュを行うためのOSSのDockerイメージです。
Googleが開発しているようですが、公式サポートはしていないようです。
READMEを見ると各クラウド環境のレジストリへのプッシュにも対応しており、使いやすそうな印象です。
前提条件
前回使用したEC2、ECR、ソースコードをそのまま使用します。
Ansibleで直接ECRにプッシュしていた箇所を、Kanikoポッドでプッシュするように変更してみます。
KanikoポッドがECRにイメージをプッシュするには、稼働環境(EC2/EKS)にIAMロールを付与するか、IAMロールが付与されたユーザーのクレデンシャルをコンテナに渡す必要があります。
今回は前回と同じユーザーを使用するため、クレデンシャルのSecretを作成しました。
$ k create secret generic aws-secret --from-file=.aws/credentials -n ansible-test
AWS ECR周りの設定は、この辺りに詳細が記載されています。
ディレクトリ構成
.
├─ deploy-image.yml 実行するAnsible playbook
├─ Dockerfile プッシュするイメージのDockerfile
├─ Jenkinsfile イメージに含めるJenkinsfile
├─ inventory
│ └─ hosts
└─ roles
└─ k8s-kaniko
└─ tasks
├─ kaniko.yml Kanikoポッドを立ち上げる為のマニフェスト
└─ main.yml Ansibleのロール
実装
記載のないファイルの内容は前回と同様です。
deploy-image.yml
roleを含めるだけのplaybookです。
--- - name: k8s kaniko Test hosts: local roles: - k8s-kaniko
roles/k8s-kaniko/tasks/main.yml
DockerfileとJenkinsfileをKanikoコンテナに渡す必要があるため、ConfigMapにしてからVolume経由でコンテナに渡す想定です。
1つのConfigMapに纏めようとしたのですが、yamlのパースエラーが起きるので2つに分けています。
改行+インデントがうまく設定できるようなコマンドを含めれば解消できそうですが、今回はそこまでの作りこみはしません。
--- - name: "Build docker image in k8s cluster" debug: msg: "Build docker image in k8s cluster" - name: Install boto3 pip: name: boto3 state: present - name: Slurp Dockerfile slurp: path: Dockerfile register: cat_Dockerfile - name: Slurp Jenkinsfile slurp: path: Jenkinsfile register: cat_Jenkinsfile - name: Create config-map in Dockerfile k8s: kubeconfig: ~/.kube/config state: present resource_definition: apiVersion: v1 kind: ConfigMap metadata: name: kaniko-test-cm-docker namespace: ansible-test data: Dockerfile: "{{ cat_Dockerfile.content | b64decode }}" - name: Create config-map in Jenkinsfile k8s: kubeconfig: ~/.kube/config state: present resource_definition: apiVersion: v1 kind: ConfigMap metadata: name: kaniko-test-cm-jenkins namespace: ansible-test data: Jenkinsfile: "{{ cat_Jenkinsfile.content | b64decode }}" - name: Create repository ecs_ecr: name: "{{ image_name }}" aws_access_key: "{{ key_id }}" aws_secret_key: "{{ access_key }}" region: "{{ region }}" register: ecr_repo - name: Push docker image vars: imagename: "{{ ecr_repo.repository.repositoryUri }}:{{ image_version }}" namespace: ansible-test k8s: definition: '{{ item }}' kubeconfig: ~/.kube/config state: present loop: - "{{ lookup('template', 'kaniko.yml') | from_yaml_all | list }}"
kaniko.yml
Kanikoポッドを立ち上げる為のマニフェストファイルです。
使い方の詳細はGitHubのREADMEに記載されています。
apiVersion: v1 kind: Pod metadata: name: kaniko namespace: {{namespace}} spec: restartPolicy: Never containers: - name: kaniko image: gcr.io/kaniko-project/executor:latest args: - "--dockerfile=./Dockerfile" - "--context=/kaniko-test-cm" - "--destination={{ imagename }}" volumeMounts: - name: aws-secret mountPath: /root/.aws readOnly: true - name: kaniko-test-cm mountPath: /kaniko-test-cm readOnly: true volumes: - name: aws-secret secret: secretName: aws-secret - name: kaniko-test-cm projected: sources: - configMap: name: kaniko-test-cm-docker - configMap: name: kaniko-test-cm-jenkins
playbook実行
正常終了することを確認。
$ ansible-playbook deploy-image.yml -i inventory/hosts
PLAY [k8s kaniko Test] *************************************************************************************************
TASK [Gathering Facts] *************************************************************************************************
ok: [localhost]
TASK [k8s-kaniko : Build docker image in k8s cluster] ******************************************************************
ok: [localhost] => {
"msg": "Build docker image in k8s cluster"
}
TASK [k8s-kaniko : Install boto3] **************************************************************************************
ok: [localhost]
TASK [k8s-kaniko : Slurp Dockerfile] ***********************************************************************************
ok: [localhost]
TASK [k8s-kaniko : Slurp Jenkinsfile] **********************************************************************************
ok: [localhost]
TASK [k8s-kaniko : Create config-map in Dockerfile] ********************************************************************
ok: [localhost]
TASK [k8s-kaniko : Create config-map in Jenkinsfile] *******************************************************************
ok: [localhost]
TASK [k8s-kaniko : Create repository] **********************************************************************************
ok: [localhost]
TASK [k8s-kaniko : Push docker image] **********************************************************************************
changed: [localhost] => (item=[{u'kind': u'Pod', u'spec': {u'restartPolicy': u'Never', u'volumes': [{u'secret': {u'secretName': u'aws-secret'}, u'name': u'aws-secret'}, {u'name': u'kaniko-test-cm', u'projected': {u'sources': [{u'configMap': {u'name': u'kaniko-test-cm-docker'}}, {u'configMap': {u'name': u'kaniko-test-cm-jenkins'}}]}}], u'containers': [{u'image': u'gcr.io/kaniko-project/executor:latest', u'args': [u'--dockerfile=./Dockerfile', u'--context=/kaniko-test-cm', u'--destination=xxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/jenkins-test/jenkins-test:v1.0.0'], u'volumeMounts': [{u'readOnly': True, u'mountPath': u'/root/.aws', u'name': u'aws-secret'}, {u'readOnly': True, u'mountPath': u'/kaniko-test-cm', u'name': u'kaniko-test-cm'}], u'name': u'kaniko'}]}, u'apiVersion': u'v1', u'metadata': {u'namespace': u'ansible-test', u'name': u'kaniko'}}])
PLAY RECAP *************************************************************************************************************
localhost : ok=9 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
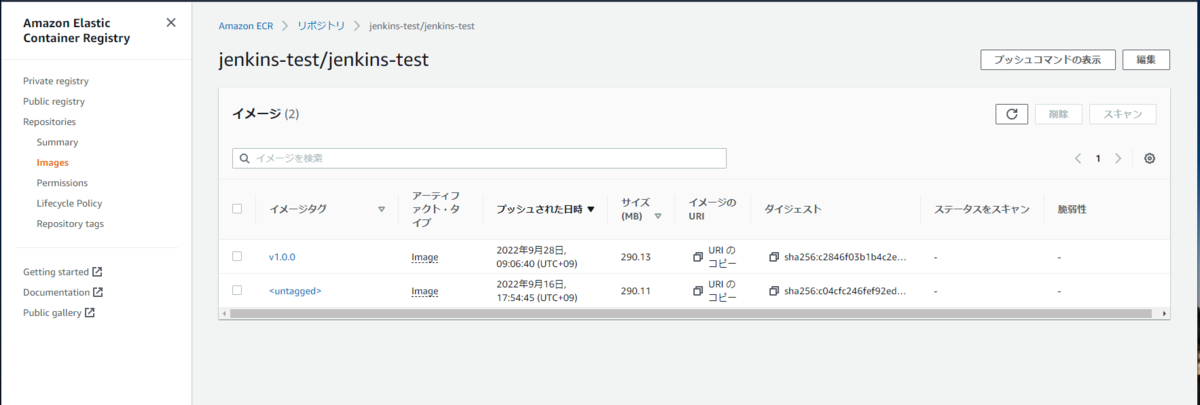
コンソールからECRにイメージがプッシュされたことが確認できます。
注意
issuesやプルリクから察するに、メンテナンスはあまり活発に行われていないように思います。
また、最近のissuesの中にはマルチステージビルドに失敗する等、クリティカルな内容の物も見受けられます。
もし技術選定に関われる立場にあるなら、できる限りKanikoは使用しない設計に倒した方が無難でしょう。
【AWS】ansibleでECRにDockerイメージをpushして、EKS環境にデプロイする

目的
前提条件
- 作業する環境に
PythonとAnsible、kubectlのインストールが必要 aws eks update-kubeconfig ...でconfigが作成済み
# Ansibleのk8sモジュールを使用する際に必要なライブラリ
$ pip install pyyaml kubernetes openshift
参考
こちらの記事を参考にEKS環境を構築しました。
変更点は以下となります。
- 社用アカウントのVPC数が上限に達していたので、
CloudFormationによるデプロイはせず、既存のVPCを利用 - addonのコンテナを起動するとセカンダリIPが不足するので、ノードグループのインスタンスタイプを
t3.mediumに変更- 使用しないときはAutoScalingのノード数を
0に設定すると、ノードが停止します
- 使用しないときはAutoScalingのノード数を
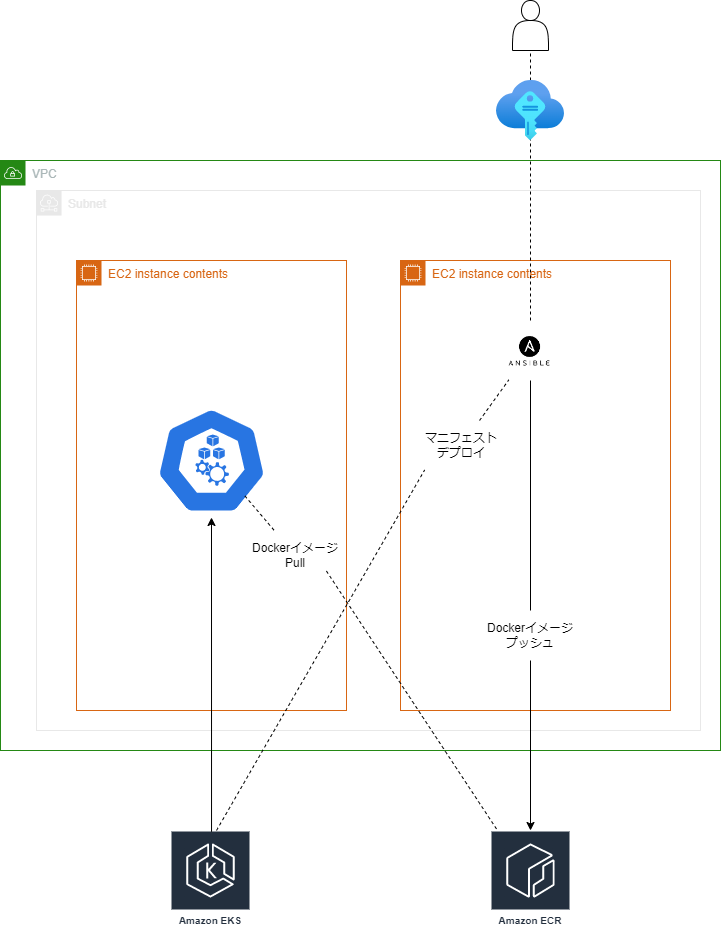
構成図
ディレクトリ構成
とりあえず、必要最低限のファイルを用意しました。
ディレクトリ構成について、公式がベストプラクティスを定義していますので、そちらが参考になります。
. ├── local.yml # site.yml から呼び出されて実行されるファイル ├── site.yml # 本YAMLファイルから、[任意の処理名].ymlを呼び出す。 ├── Dockerfile # pushするDockerイメージ ├── inventory # ホストとそれに紐づく変数を定義するファイル │ └── hosts └── roles # Playbookのタスクetc...を格納。詳細は公式ドキュメント参照。 ├── ... └── k8-jenkins # role毎にディレクトリを用意すると良さそう。 └── tasks ├── deployment.yml # EKSへデプロイするマニフェスト。 └── main.yml # Dockerイメージのビルドやpush等の実処理を記載するファイル。
実装
site.yml
実行ファイルをインポート。
--- - import_playbook: local.yml
local.yml
実行対象のroleをrolesの配列に含める。
ansible.kubernetes-modulesはk8sデプロイモジュールを利用する際に必要になります。
先にインストール済みの環境であれば、不要かも?
--- - name: Ansible Test hosts: local roles: - ansible.kubernetes-modules - k8s
inventory/hosts
ローカル環境の定義のみ記載しています。
ベストプラクティスによると、変数定義はgroup_varsやhost_varsディレクトリに纏めて配置するようです。
クレデンシャル管理はPJの方針に従ってください。
また、最初はinventoriesという名前のディレクトリにしていたのですが、--syntax-chek実行時に警告?が出ていたので、とりあえずinventoryとしています。
[local] localhost ansible_connection=local [local:vars] region=ap-northeast-1 key_id=xxxxxxxx access_key=xxxxxxxx image_name=jenkins-test/jenkins-test image_version=v1.0.0
roles/k8s/tasks/main.yml
AWSコマンドを使用する為、configなどの配置も併せて行っています。
埋め込み文字は Jinja2 構文 で変数が展開されます。
--- - name: "Push Docker image to AWS ECR" debug: "Push Docker image to AWS ECR" - name: Make aws directory file: dest: ~/.aws state: directory mode: u=rwx,g=o= - name: Copy aws config template: src: aws/config dest: ~/.aws/config mode: u=rw,g=o= - name: Copy aws credentitals template: src: aws/credentitals dest: ~/.aws/credentitals mode: u=rw,g=o= - name: Install docker-py for build Docker pip: name: docker-py state: present - name: Build Docker image docker_image: build: path: ./ name: "{{ image_name }}" tag: "{{ image_version }}" - name: Docker login shell: "aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin <ユーザーID>.dkr.ecr.ap-northeast-1.amazonaws.com" args: executable: /bin/bash - name: Install boto3 pip: name: boto3 state: present - name: Create repository ecs_ecr: name: "{{ image_name }}" aws_access_key: "{{ key_id }}" aws_secret_key: "{{ access_key }}" region: "{{ region }}" register: ecr_repo - name: Add tag docker_image: name: "{{ image_name }}:{{ image_version }}" repository: "{{ ecr_repo.repository.repositoryUri }}" tag: "{{ image_version }}" - name: Push image to ECR docker_image: name: "{{ ecr_repo.repository.repositoryUri }}:{{ image_version }}" push: yes - name: Create deployment to EKS vars: imagename: "{{ ecr_repo.repository.repositoryUri }}:{{ image_version }}" replica: 1 namespace: ansible-test k8s: definition: '{{ item }}' kubeconfig: ~/.kube/config state: present loop: - "{{ lookup('template', 'deployment.yml') | from_yaml_all | list }}"
roles/k8s/tasks/deployment.yml
EKSへデプロイするマニフェストファイル。
ジョブで定義したvarsの各値がマニフェストの埋め込み文字に反映されます。
apiVersion: apps/v1 kind: Deployment metadata: name: test-jenkins-app namespace: {{ namespace }} spec: replicas: {{ replica }} selector: matchLabels: app: test-jenkins-app minReadySeconds: 10 template: metadata: labels: app: test-jenkins-app spec: volumes: - name: git-secret-volume secret: secretName: git-secret containers: - image: {{ imagename }} name: jenkins-test-container restartPolicy: Always ports: - containerPort: 8080 resources: requests: cpu: 200m memory: 20Mi limits: cpu: 512m memory: 500Mi volumeMounts: - name: git-secret-volume mountPath: /var/jenkins_home/.ssh readOnly: true --- apiVersion: v1 kind: Service metadata: name: test-jenkins-service namespace: {{ namespace }} labels: app: test-jenkins-service spec: type: LoadBakancer ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: test-jenkins-app
Dockerfile
とりあえずJenkinsを動かしてみます。
FROM jenkins/jenkins:latest
RUN mkdir -p /var/jenkins_home/.ssh && ¥
chown -R jenkins:jenkins /var/jenkins_home
COPY --chown=jenkins:jenkins ./Jenkinsfile ./
playbook実行
各ジョブが正常終了することを確認。
$ ansible-playbook site.yml -i inventory/hosts PLAY [Ansible Test] ******************************************************************************************************************** TASK [Gathering Facts] ***************************************************************************************************************** [WARNING]: Platform linux on host localhost is using the discovered Python interpreter at /usr/bin/python, but future installation of another Python interpreter could change this. See https://docs.ansible.com/ansible/2.9/reference_appendices/interpreter_discovery.html for more information. ok: [localhost] TASK [ansible.kubernetes-modules : Install latest openshift client] ******************************************************************** skipping: [localhost] TASK [k8s : push docker image to ECR & deploy to EKS] ****************************************************************************** ok: [localhost] => { "msg": "push docker image to AWS ECR & deploy to EKS" } TASK [k8s : make aws directory] ******************************************************************************************************** ok: [localhost] TASK [k8s : copy aws config] *********************************************************************************************************** ok: [localhost] TASK [k8s : copy aws credentials] ****************************************************************************************************** ok: [localhost] TASK [k8s : install docker-py for build docker] **************************************************************************************** ok: [localhost] TASK [k8s : build docker image] ******************************************************************************************************** [WARNING]: The value of the "source" option was determined to be "build". Please set the "source" option explicitly. Autodetection will be removed in Ansible 2.12. ok: [localhost] TASK [k8s : docker login] ************************************************************************************************************** changed: [localhost] TASK [k8s : install boto3] ************************************************************************************************************* ok: [localhost] TASK [k8s : create repository] ********************************************************************************************************* ok: [localhost] TASK [k8s : add tag] ******************************************************************************************************************* [WARNING]: The value of the "source" option was determined to be "pull". Please set the "source" option explicitly. Autodetection will be removed in Ansible 2.12. ok: [localhost] TASK [k8s : push image to ecr] ********************************************************************************************************* ok: [localhost] TASK [k8s : Create a Deployment to EKS] ************************************************************************************************ ok: [localhost] => (item=[{u'kind': u'Deployment', u'spec': {u'selector': {u'matchLabels': {u'app': u'test-jenkins-app'}}, u'minReadySeconds': 10, .... u'spec': {u'type': u'LoadBalancer', u'ports': [{u'targetPort': 8080, u'protocol': u'TCP', u'port': 80}], u'selector': {u'app': u'test-jenkins-app'}}, u'apiVersion': u'v1', u'metadata': {u'labels': {u'app': u'test-jenkins-service'}, u'namespace': u'ansible-test', u'name': u'test-jenkins-service'}}]) PLAY RECAP ***************************************************************************************************************************** localhost : ok=13 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
コンテナの起動確認
参考サイトや公式ドキュメントの手順通りに設定していれば、IAMの設定はできていると思います。
$ alias k=kubectl $ k get pod --namespace ansible-test NAME READY STATUS RESTARTS AGE test-jenkins-app-7c7ffcfb46-fq5q6 1/1 Running 0 46m # コンテナにログインして、jenkinsのinitialAdminPasswordを確認 $ k exec -it test-jenkins-app-7c7ffcfb46-fq5q6 -n ansible-test -- /bin/bash jenkins@test-jenkins-app-7c7ffcfb46-fq5q6:/$ cat /var/jenkins_home/secrets/initialAdminPassword xxxxxxxxxxxxxxxxxxxxxxxxxxx jenkins@test-jenkins-app-7c7ffcfb46-fq5q6:/$ exit exit # アクセス先を確認 $ k get service --namespace ansible-test NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE test-jenkins-service LoadBalancer 10.100.138.217 ac7d2f38812bc41d7bf81a39a4a7c467-1945438877.ap-northeast-1.elb.amazonaws.com 80:32108/TCP 3d17h
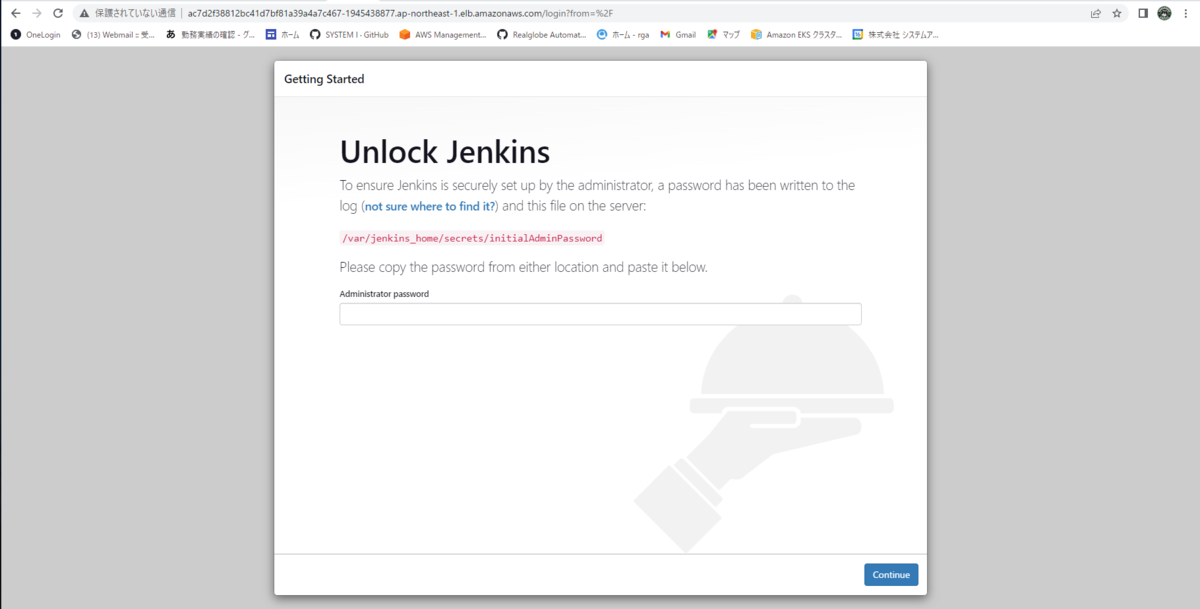
http://<EXTERNAL-IP>にアクセスすると、jenkinsの初期画面が表示される。
HTTPS接続にしたい場合、ACMで証明書を作成すると良いでしょう。
【Docker】PythonのAWS LambdaLayerをDockerで作成する

AWS LambdaのLayerモジュールをzip化するまでの処理をDockerで行えるようにしたので、その方法をメモ。
Dockerfile
amazonlinuxのイメージを利用することで、EC2などを用意せずにx86_64のアーキテクチャに対応させます。
Pythonのバージョンは適宜変更する。
FROM amazonlinux
ENV PATH $PATH:/usr/local/bin
RUN yum -y install ¥
gcc openssl-devel bzip2-devel libffi-devel ¥
wget tar gzip zip make && ¥
wget https://www.python.org/ftp/python/3.9.11/Python-3.9.11.tgz && ¥
tar xzf Python-3.9.11.tgz && ¥
cd Python-3.9.11 && ¥
./configure --enable-optimizations && ¥
make altinstall
RUN mkdir ./python-src && ¥
python3.9 -m pip install xxx... -t ./python-src
COPY . ./
RUN zip -r /tmp/aws-layer.zip ./python-src
起動スクリプト
zipファイルをカレントディレクトリに配置するまでを自動化。
#/bin/sh IMAGE_NAME=aws-layer:0.0.0 CONTAINER=aws-layer-con docker stop $CONTAINER docker rm $CONTAINER docker build -t $IMAGE_NAME . --no-cache docker run -itd --name $CONTAINER $IMAGE_NAME docker cp $CONTAINER:/tmp/layer.zip .
【Oracle Cloud】ORA-28001: the password has expiredの際の対処方法【Oracle Autonomous Database】

Oracle Cloudで稼働させているOracleDBがパスワードの有効期限切れで落ちるようになっていたので、対処方法をメモ。
sqlplusのインストール
yumでsqlplusをインストールします。
バージョンは使用しているDBと同じものを選択してください。
[opc@xxxxx ~]$ yum search sqlplus /usr/lib/python2.7/site-packages/OpenSSL/crypto.py:12: CryptographyDeprecationWarning: Python 2 is no longer supported by the Python core team. Support for it is now deprecated in cryptography, and will be removed in the next release. from cryptography import x509 読み込んだプラグイン:langpacks, ulninfo ===================================================================================== N/S matched: sqlplus ====================================================================================== oracle-instantclient12.2-sqlplus.x86_64 : SQL*Plus for Instant Client. oracle-instantclient18.3-sqlplus.x86_64 : SQL*Plus for Instant Client. oracle-instantclient18.5-sqlplus.x86_64 : SQL*Plus for Instant Client. oracle-instantclient19.10-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.11-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.12-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.13-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.14-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.15-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.3-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.5-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.6-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.8-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package oracle-instantclient19.9-sqlplus.x86_64 : Oracle Instant Client SQL*Plus package Name and summary matches only, use "search all" for everything. [opc@xxxxx ~]$ yum install oracle-instantclient19.X-sqlplus.x86_64
sqlplusからパスワードを更新
以下のコマンドでパスワードを更新します。 更新後のパスワードで問題なく接続できることが確認できたら、作業は完了です。
[opc@xxxxx ~]$ sqlplus ADMIN/{パスワード}@xxxxxxxx0_high
SQL> alter user {ユーザー名} identified by "{新しいパスワード}";
User altered.
SQL> ALTER USER {ユーザー名} ACCOUNT UNLOCK;
User altered.
# 開発の現場では、あまりやらない方が良いかも
SQL> ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;
Profile altered.
SQL> exit;